
PythonでPDFを簡単に結合する方法
みるみる
インフラエンジニアめも

PythonでTwitterからツイートを取得して、テキストを分析して、出現頻度が多い単語を簡単に取得します。
また環境はAWSのCloud9を利用しておりますので、WindowsやMac等の端末で利用する場合は、手順が異なりますので、ご注意ください。
https://aws.amazon.com/jp/cloud9/
流れとしては、
です。
Contents
事前準備は以下の順序で進めていきます。
Twitter APIを実行するには、開発者情報を申請し、「Consumer API Keys」、「アクセストークン情報」の情報を取得する必要があります。
すべて英語であったため、申請には一苦労ですが、頑張って必須項目を入力します。
私はGoogle翻訳しながら、頑張りましたが、詳細に説明して頂いているサイトがありましたので、手順通りにやれば、申請が完了します。
https://qiita.com/kngsym2018/items/2524d21455aac111cdee
■以下のコマンドを実行
sudo python3 -m pip install tweepy
■実行結果
ec2-user:~/environment $ sudo python3 -m pip install tweepy Collecting tweepy Using cached tweepy-3.8.0-py2.py3-none-any.whl (28 kB) Requirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.6/site-packages (from tweepy) (1.14.0) Requirement already satisfied: PySocks>=1.5.7 in /usr/local/lib/python3.6/site-packages (from tweepy) (1.7.1) Requirement already satisfied: requests-oauthlib>=0.7.0 in /usr/local/lib/python3.6/site-packages (from tweepy) (1.3.0) Requirement already satisfied: requests>=2.11.1 in /usr/local/lib/python3.6/site-packages (from tweepy) (2.22.0) Requirement already satisfied: oauthlib>=3.0.0 in /usr/local/lib/python3.6/site-packages (from requests-oauthlib>=0.7.0->tweepy) (3.1.0) Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/site-packages (from requests>=2.11.1->tweepy) (2019.11.28) Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/site-packages (from requests>=2.11.1->tweepy) (1.25.9) Requirement already satisfied: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/site-packages (from requests>=2.11.1->tweepy) (3.0.4) Requirement already satisfied: idna<2.9,>=2.5 in /usr/local/lib/python3.6/site-packages (from requests>=2.11.1->tweepy) (2.8) Installing collected packages: tweepy Successfully installed tweepy-3.8.0
導入後に、実際にTweepyでデータが取得できるか確認しましょう。確認するためのソースは以下の参照サイトを利用ください。
私自身のツイートを取得したものは以下となります。
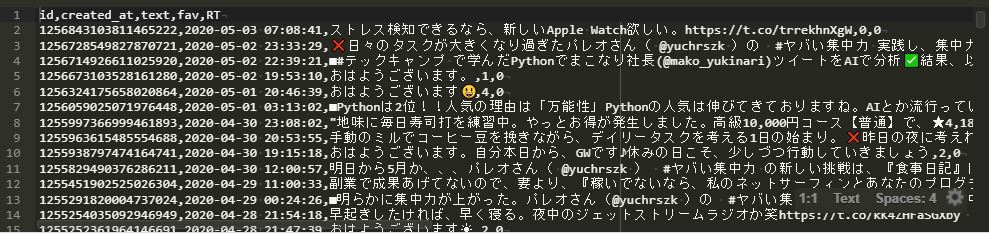
Mecabのインストールには、以下のコマンドを実行します。
sudo python3 -m pip install mecab-python3
ec2-user:~/environment $ sudo python3 -m pip install mecab-python3
Collecting mecab-python3
Downloading mecab_python3-0.996.5-cp36-cp36m-manylinux2010_x86_64.whl (17.1 MB)
|████████████████████████████████| 17.1 MB 48 kB/s
Installing collected packages: mecab-python3
Successfully installed mecab-python3-0.996.5
WordCloudをインストールします。
sudo python3 -m pip install wordcloud
以下のような結果となります。
ec2-user:~/environment $ sudo python3 -m pip install wordcloud
Collecting wordcloud
Downloading wordcloud-1.7.0-cp36-cp36m-manylinux1_x86_64.whl (364 kB)
|████████████████████████████████| 364 kB 10.3 MB/s
Collecting pillow
Downloading Pillow-7.1.2-cp36-cp36m-manylinux1_x86_64.whl (2.1 MB)
|████████████████████████████████| 2.1 MB 17.4 MB/s
Collecting numpy>=1.6.1
Downloading numpy-1.18.3-cp36-cp36m-manylinux1_x86_64.whl (20.2 MB)
|████████████████████████████████| 20.2 MB 1.1 MB/s
Collecting matplotlib
Downloading matplotlib-3.2.1-cp36-cp36m-manylinux1_x86_64.whl (12.4 MB)
|████████████████████████████████| 12.4 MB 47 kB/s
Requirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.6/site-packages (from matplotlib->wordcloud) (2.8.1)
Collecting kiwisolver>=1.0.1
Downloading kiwisolver-1.2.0-cp36-cp36m-manylinux1_x86_64.whl (88 kB)
|████████████████████████████████| 88 kB 8.4 MB/s
Collecting cycler>=0.10
Downloading cycler-0.10.0-py2.py3-none-any.whl (6.5 kB)
Collecting pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1
Downloading pyparsing-2.4.7-py2.py3-none-any.whl (67 kB)
|████████████████████████████████| 67 kB 8.4 MB/s
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.6/site-packages (from python-dateutil>=2.1->matplotlib->wordcloud) (1.14.0)
Installing collected packages: pillow, numpy, kiwisolver, cycler, pyparsing, matplotlib, wordcloud
WARNING: The scripts f2py, f2py3 and f2py3.6 are installed in '/usr/local/bin' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
WARNING: The script wordcloud_cli is installed in '/usr/local/bin' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed cycler-0.10.0 kiwisolver-1.2.0 matplotlib-3.2.1 numpy-1.18.3 pillow-7.1.2 pyparsing-2.4.7 wordcloud-1.7.0
Mecabが正常に動作するか確認します。
ec2-user:~/environment $ python3
Python 3.6.10 (default, Feb 10 2020, 19:55:14)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import MeCab
>>> mecab = MeCab.Tagger("-Ochasen") # MeCabオブジェクトを作成
>>> malist = mecab.parse("すもももももももものうち") # 形態素解析を行う
>>> print(malist)
すもも スモモ すもも 名詞-一般
も モ も 助詞-係助詞
もも モモ もも 名詞-一般
も モ も 助詞-係助詞
もも モモ もも 名詞-一般
の ノ の 助詞-連体化
うち ウチ うち 名詞-非自立-副詞可能
EOS
データ取得に際しては、以下を参考にしました。
https://qiita.com/i_am_miko/items/a2e5168e619ed37afeb9
あと、ツイート数が多い場合は、エラーとなるため、エラーとなった場合は15分間待つ必要があります。
https://qiita.com/non-caffeine/items/299cccf22d074ad27466
jupyter Notebookの設定方法は以下を確認ください。

jupyter Notebookを用いて、いいねの平均値を取得し、平均値以上のツイートのみを分析対象としております。
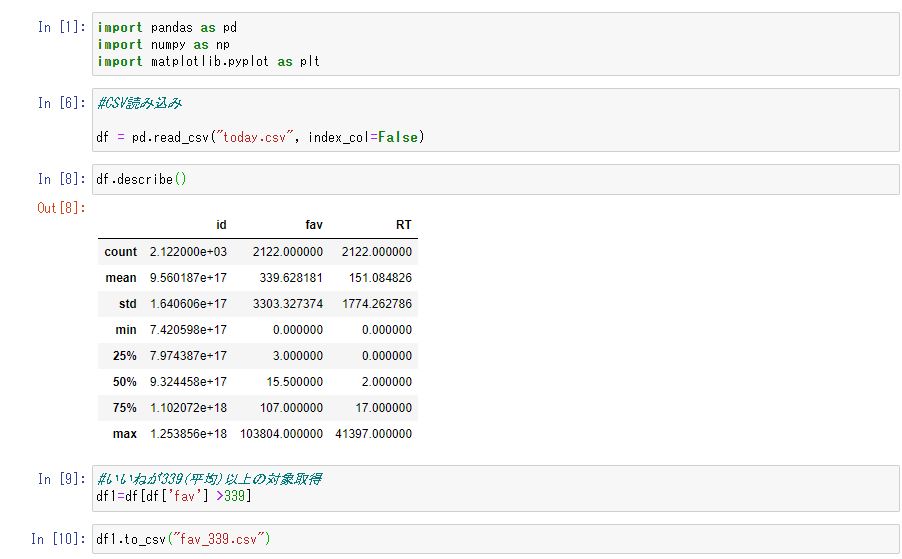
WordCloudと頻出語句を取得するスクリプトは以下となります。
import MeCab
import sys
import re
from collections import Counter
import csv
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import matplotlib.font_manager # 文字化け対策
import japanize_matplotlib
def keitaiso_mecab(infile):
#csvファイル読み込み
with open(infile) as f:
timelines = f.read()
#整形httpsから始まる文字を削除
#参照:https://www.megasoft.co.jp/mifes/seiki/s310.html
text=re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", timelines)
# *が多いため、削除
text.strip("*")
# MeCabを使用してテキストを形態素解析
m = MeCab.Tagger ('-Ochasen')
node = m.parseToNode(text)
words=[]
while node:
hinshi = node.feature.split(",")[0]
if hinshi in ["名詞","動詞","形容詞"]:
# if hinshi in ["名詞"]:
origin = node.feature.split(",")[6]
words.append(origin)
node = node.next
#stopwordの指定
stop_words = ["てる", "の", "れる", "られる","これ", "それ","さ", "ん", "こちら", "い", "がる", "こと" ]
words = [word for word in words if word not in stop_words]
return words
def csv_write(csv_file_name,counter,words):
word_list = []
count_list = []
#csvファイルへ書き込み
with open(csv_file_name, 'w') as f:
writer = csv.writer(f)
writer.writerow(['word','count'])
#csvファイルのヘッダーを設定
#top10取得用
i=0
for word, count in counter.most_common():
#*が不要のため、除外
if word !="*":
writer.writerow([word,count])
#20位のみ取得
if word!= i < 20:
#図示作成用
word_list.append(word)
count_list.append(count)
i=i+1
pltbarh(word_list,count_list)
def wordcloud(words,fpath):
#wordcloud
#wordcloudのために、文字列を結合
wordC_text = ' '.join(words)
wordcloud = WordCloud(background_color="white",font_path=fpath, width=900, height=500).generate(wordC_text)
wordcloud.to_file("./wordcloud_sample.png")
####top10のみ図示する
def pltbarh(word_list,count_list):
#配列逆順
word_list.reverse()
count_list.reverse()
plt.rcParams['font.family'] = 'IPAexGothic'
plt.barh(word_list, count_list)
plt.xlabel("word")
plt.ylabel("count")
plt.savefig('figure.png')
def main():
# テキストファイルの読み込み
infile='fav_339.csv'
fpath='NotoSansCJKjp-Regular.otf'
csv_file_name='mecab.csv'
words = []
words=keitaiso_mecab(infile)
# カウントの降順で出力(カンマ区切り)
counter = Counter(words)
csv_write(csv_file_name,counter,words)
wordcloud(words,fpath)
if __name__ == "__main__":
main()
実際に取得して、分析した結果は以下を参考にしてみてください。まこなり社長のツイート分析をしたものがありますので、楽しんでみていただければと思います。
WordCloudで図示してもの。

TOP20の頻出単語を抽出したもの。
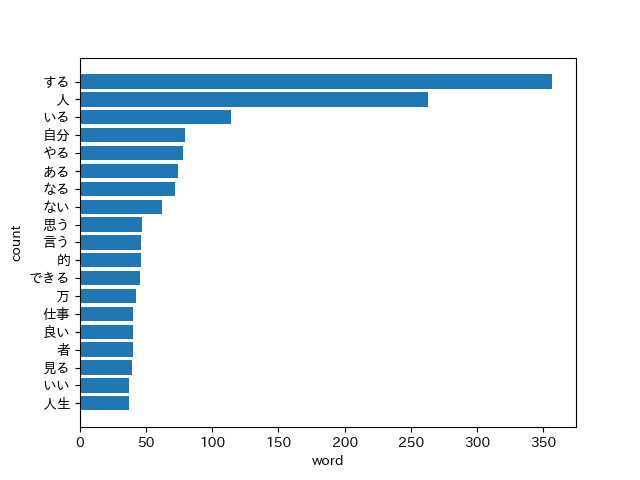
詳細は以下にまとめております。
結果としては、頻出語は以下となりました。Pythonを利用すれば、簡単に頻出語を取得し、どのようなツイートをしているのかということが分析することができます。
また簡単に図示もすることができるので、データ分析をする助けにもなりますね。あなたも気になったデータがあれば、データの傾向がどうなっているのか?といったことを分析してみるのもいいかもしれません。




